登录以参加训练计划
前面两节我们学了一维数组和二维数组。我们知道,无论数组的下标有几个,类型如何,数组中全体元素的类型必须相同。 数组元素的类型可以是任何类型,当它是字符型时,我们称它为字符数组。字符数组与字符类型是计算机处理非数值的重要数据类型 ,因此我们放在一起讨论。
特别注意:在C语言中没有内置的string数据类型 。在 C 中通常使用字符数组来表示字符串。字符串实际上是一系列字符,以空字符 \0 结束。
为了处理字符串,C 提供了 <string.h> 头文件,其中包含了许多用于操作字符串的函数,如 strlen, strcpy, strcat, strcmp 等等。
下面是一个简单的示例,展示了如何在 C 语言中声明一个字符串并使用 scanf 输入:
#include <stdio.h>
#include <string.h>
int main() {
char str[100]; // 定义一个可以容纳最多99个字符加上终止符'\0'的字符数组
printf("Enter a string: ");
fgets(str, sizeof(str), stdin); // 使用fgets代替scanf来读取整个行
str[strcspn(str, "\n")] = 0; // 去除末尾的换行符
printf("You entered: %s\n", str);
return 0;
}
在上面这个例子中:
char str[100]; 定义了一个字符数组 str,它可以存储最多 99 个字符加上一个空字符 \0。
fgets(str, sizeof(str), stdin); 用于读取一行文本到 str 中。这里我们使用 sizeof(str) 来指定 str 数组的最大长度。
str[strcspn(str, "\n")] = 0; 用于去除字符串末尾可能存在的换行符,这样 str 就不会包含额外的字符。
注意:通常不推荐使用 scanf 来读取字符串,因为它很难控制输入,并且容易导致缓冲区溢出。例如,如果用户输入的字符串超过了数组的大小,那么可能会导致未定义行为。因此,使用 fgets 是更安全的选择。
1,字符类型
字符类型是由一个字符组成的字符常量或字符变量。 字符常量定义:
const char 字符常量=`字符`;
字符变量定义:
char 字符变量;
注意:字符类型是一个有序类型,'字符的大小顺序按其ASCII码的大小而定。
下图是ASCII表,通过这个表我们知道256个字符对应的整数是哪个? 常用的’0‘表示是48;'A'为65;'a'为97;
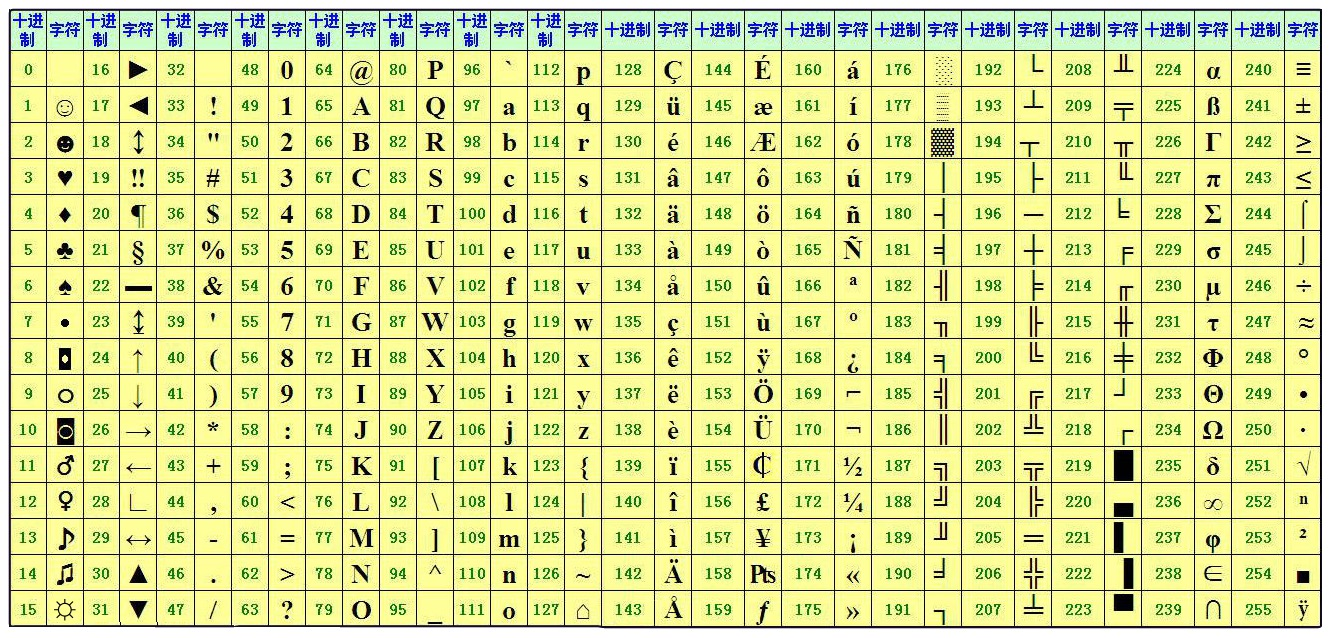
下面程序中,我们利用字符类型是顺序类型这一特性,灵活利用字符变量当作循环变量。
#include<iostream>
#include<iomanip>
using namespace std;
int main(){
for(char c='a';c<='z';c+=2){
cout<<setw(3)<<c;
cout<<endl;
for(char c='z';c>='a';c-=2){
cout<<setw(3)<<c;
}
return 0;
}
}
2,字符数组
字符数组是指元素类型为字符的数组。字符数组是用来存放字符序列或字符串的。字符数组也有一维、二维、三维之分。
1.字符数组的定义格式
字符数组的定义格式同一般数组的定义格式一样,第一个元素同样也是从ch1[0]开始,所不同的是数组类型是字符类型。
2.字符数组的赋值
字符数组的赋值类似于一维数组,分为数组的初始化和数组元素的赋值。另外初始化的方式有字符初始化和用字符串初始化两种。
(1)字符初始化:初始值表中的每个数据项是一个字符,当初始值个数少于元素个数时,从首元素开始赋值,剩余元素默认为空字符。
字符数组中也可以存放若干个字符,也可以来存放字符串。两者的区别是字符串有一个结束符“\0”。反过来说,在一维字符数组中存放着带有结束符的若个字符称为字符串。字符串是一维数组,但是一维数组不等于字符串。
例如:
char chr2[5]={'a','b','c','d','\0'};//在数组chr2中存放着一个字符串"abcd"。
(2)用字符串初始化数组。 用一个字符串初始化一个一维字符数组,可以写成下列形式:
char chr2[5] ="abcd";
使用此格式均要注意字符串的长度应小于字符数组的大小或等于字符数组的大小减1。同理,对二维字符数组来讲,可存放若干个字符串。可使用由若干个字符串组成的初始值表给二维字符数组初始化。
例如:char ch3[3][4]={"abc","mno","xyz"};在数组ch3中存放3个字符串,每个字符串的长度不得大于3。
(3)数组元素赋值 字符数组的赋值是给该字符数组的各个元素赋一个字符值。 例如:
char chr[3];
chr[0]='a';chr[1]='b';chr[2]='c';
(4)字符常量与字符串常量的区别
a,两者的定界符不同,字符常量由单引号括起来,字符串常量由双引号括起来。 b,字符常量只能是单个字符,字符串常量则可以是多个字符。 c,可以把一个字符常量赋值给一个字符串变量,但不能把一个字符串常量赋值给一个字符变量。 d,字符常量占一个字节,而字符串常量点用字节数等于字符串的字节数加1。增加的一个字节中存放字会串结束标志'\0'。
3,字符数组的输入与输出
从键盘上输入一个字符数组可以使用scanf语句或gets语句。
1,输入
(1)scanf语句
格式:scanf("%s",字符数组名称); 说明: a,这里的字符串名称之前不加&这个取地址符号。例如:scanf("%s",&s1)是错误的;
b,系统会自动在输入的字符串常量后添加'\0'标志,因此输入时,仅输入字符串的内容即可。
c,输入多个字符串时,以空隔分隔。
例如:scanf("%s%s%s",s1,s2,s3);从键表上分别输入let us go,则三个字符串分别获取三个单词。反过来可以想到,如果仅有一个输入字符串名称不的情况下, 字符串变量仅获取空格前的内容。
例如:scanf("%s",s1);从键盘输入let us go,则仅有第一个单词被获取,即s1变量仅获得第一个单词let。
(2)gets语句(因为安全问题,在c++新版本已经不再支持,仅作了解) 格式:gets(字符串名称); 说明: 使用gets只能输入一个字符串。例如:gets(s1,s2)是错误的。使用gets是从沅标开始的地方读到换行符,也就是说读到的是一整行,而使用scanf是从光标开始的地方读到空隔,如果这一行没有空隔,才读到行尾。
例如:scanf("%s",s1);gets(s2);对于相同的输入Hello world!。s1获取的结果仅仅是Hello,而s2获取的结果是Hello world!
(3)fgests语句 格式:fgets(str, sizeof(str), stdin); 其中str是字符数组的名字。
2,输出
向屏幕输出一个字符串可以使用printf语句或puts语句。
(1)printfs语句 格式:printf("%s",字符串名称); 说明: a,用%s格式输出时,printf 的输出项只是字符串的名称,而不能是数组元素。例如:printf("%s",a[5]);是错误的。 b,输出字符串不锯括字符串结束标志符“\0”。
(2)puts语句 格式:puts(字符串名称) 说明:puts语句输出一个字符串和一个换行符。对于已经声明过的字符串a,printf("%s"\n,a)和puts(a)是等价的;
4,字符串string
与c不同的是,C++ 引入了string 类作为标准字符串类型。这个类封装了字符串的各种操作,并提供了许多成员函数,使得字符串处理更加方便和安全。
string 的特点:
安全性:string 类自动管理内存,避免了缓冲区溢出等问题。 便利性:提供了大量的成员函数,如 length, append, substr, find, compare 等。 效率:对于小字符串优化,某些实现可能直接在对象内部存储短字符串,减少内存分配开销。 可扩展性:可以通过重载运算符来轻松地进行字符串拼接、比较等操作。
#include <iostream>
#include <string>
int main() {
string str;
cout << "Enter a string: ";
getline(cin, str); // 读取一行文本
cout << "You entered: " << str << endl;
return 0;
}
在这个示例中,我们使用了string 类来创建一个字符串对象 str,并通过getline 函数读取一行文本。
下面详细介绍string的用法。
1, 基础使用
在 C++ 中,string 类是标准库提供的强大工具,用于处理字符串。要使用 string,你需要包含 头文件。
创建string 对象
#include <string>
string s1 = "Hello"; // 初始化为 "Hello"
string s2(5, 'a'); // 初始化为 "aaaaa"
string s3(s1); // 复制构造,s3 也为 "Hello"
string s4;
getline(cin,s4);
2,常用成员函数
访问元素:
char c = s1[0]; // 获取第一个字符
s1[0] = 'H'; // 修改第一个字符
获取长度:
size_t len = s1.length(); // 或者 s1.size()
拼接字符串:
s1 += " World"; // s1 变为 "Hello World"
string s4 = s1 + "!" + s2; // 拼接多个字符串
比较字符串:
bool b = s1 > s2; // 字典序比较
查找子串:
size_t pos = s1.find("World");// 查找 "World" 的位置
int pos = s1.find("world");
替换子串:
s1.replace(pos, 5, "Universe"); // 替换 "World" 为 "Universe"
//参数说明:pos:表示开始替换的位置 ,5表示从pos开始的后5位字符,“Universe”表示要替换的字符。
删除子串:
s1.erase(pos, 5); // 删除 "World"
截取子串:
string sub = s1.substr(pos, 5); // 截取 "World"
//参数说明:pos:表示开始截取的位置 ,5表示从pos开始的后5位字符。这个函数返回截取到的字符串。
字符串大写字母转小写字母
#include <iostream>
#include <string>
using namespace std;
void toLowerCase(string &str) { // 注意这里使用引用
for (char& c : str) {//注意这种写法是c++11的用法
if ('A' <= c && c <= 'Z') {
c += 32; // 将大写字母转换为小写字母
}
}
}
int main() {
string s = "Hello, World!";
toLowerCase(s); // 调用函数
cout << s << endl; // 输出修改后的字符串。
return 0;
}
高级应用
1,字符串分割 分割字符串是常见需求,可以使用 string.find 和string substr 实现。
std::vector<std::string> split(const std::string& str, char delimiter) {
std::vector<std::string> tokens;
size_t start = 0;
size_t end = str.find(delimiter);
while (end != std::string::npos) {
tokens.push_back(str.substr(start, end - start));
start = end + 1;
end = str.find(delimiter, start);
}
tokens.push_back(str.substr(start));
return tokens;
}
2, 字符串排序 对字符串进行排序,可以使用 std::sort。
#include <algorithm>
void sortString(std::string& s) {
std::sort(s.begin(), s.end());
}
3, 字符串哈希 字符串哈希是解决字符串匹配问题的有效方法之一。
const int MOD = 1e9 + 7; // 选择一个大的素数作为模数
const int BASE = 256; // 字符集大小
long long power[100001]; // 存储 BASE 的幂次方
std::string s;
void precomputePowers() {
power[0] = 1;
for (int i = 1; i <= s.size(); ++i)
power[i] = (power[i - 1] * BASE) % MOD;
}
long long hashFunction(int l, int r) {
long long h = 0;
for (int i = l; i <= r; ++i)
h = (h * BASE + s[i]) % MOD;
return h;
}
long long rollingHash(int l, int r) {
long long h = hashFunction(l, r);
if (l > 0)
h = (h - hashFunction(l - 1, l - 1) * power[r - l + 1]) % MOD;
if (h < 0) h += MOD;
return h;
}
4, 字符串算法 4.1 KMP 算法 KMP 算法是一种高效的字符串匹配算法,可以在线性时间内完成匹配。
std::vector<int> computeLPSArray(const std::string& pattern) {
int m = pattern.size();
std::vector<int> lps(m, 0);
int len = 0;
int i = 1;
while (i < m) {
if (pattern[i] == pattern[len]) {
len++;
lps[i] = len;
i++;
} else {
if (len != 0) {
len = lps[len - 1];
} else {
lps[i] = 0;
i++;
}
}
}
return lps;
}
std::vector<int> kmpSearch(const std::string& text, const std::string& pattern) {
std::vector<int> lps = computeLPSArray(pattern);
int n = text.size();
int m = pattern.size();
std::vector<int> occurrences;
int i = 0;
int j = 0;
while (i < n) {
if (text[i] == pattern[j]) {
i++;
j++;
}
if (j == m) {
occurrences.push_back(i - j);
j = lps[j - 1];
} else if (i < n && text[i] != pattern[j]) {
if (j != 0)
j = lps[j - 1];
else
i = i + 1;
}
}
return occurrences;
}
2.4 实战应用 2.4.1 字符串排序问题 给定一组字符串,按照字典序排序。
#include <vector>
#include <algorithm>
bool compareStrings(const std::string& a, const std::string& b) {
return a < b; // 字典序比较
}
int main() {
std::vector<std::string> strings = {"banana", "apple", "orange"};
std::sort(strings.begin(), strings.end(), compareStrings);
for (const auto& s : strings)
std::cout << s << std::endl;
return 0;
}
2.4.2 字符串匹配问题 给定文本串 T 和模式串 P,找出所有 P 在 T 中出现的位置。
#include <iostream>
#include <vector>
#include <string>
int main() {
std::string T, P;
std::cin >> T >> P;
std::vector<int> positions = kmpSearch(T, P);
for (int pos : positions)
std::cout << pos << " ";
return 0;
}
- 参加人数
- 13
- 创建人
-
 junnyfan
junnyfan